Oracle9i: Wichtiges zur Architektur - um Backup und Recovery zu verstehen |
![]()
Die Architektur von Oracle
Dieser Artikel beschäftigt sich mit den Konzepten und Strukturen, also dem 'Gerippe' einer Oracle-Datenbank. Ein gewisses Grundverständnis der Architektur eines Oracle-Servers ist wichtig, um die anderen Features von Oracle verstehen zu können. Hier erkläre ich vor allem die Oracle-Bestandteile, die Backup und Recovery ermöglichen. Wissen über die Oracle-Architektur ist der Schlüssel zum Verständnis von Oracle Backup- und Recovery-Strategien.
Oracle hatte anfangs kein Standalone-Backup-Tool wie etwa ontape von Informix
oder dump von Sybase. Stattdessen wurde eine Politik verfolgt, die es dem Datenbankadministrator
(DBA) erlauben sollte, mithilfe von Befehlen an der Kommandozeile zu arbeiten
und/oder Third-Party-Backup-Programme zu nutzen.
Mit Oracle 7 wurde dann EBU eingeführt (Enterprise Backup Utility), das
aber ebenso darauf ausgelegt war, auch mit anderen kommerziellen Backup-Tools
zusammenzuarbeiten.
Seite Oracle8 gibt es den Recovery Manager (rman), der auch sehr gut mit kommerziellen
Backup-Tools zusammenarbeitet, darüber hinaus aber noch mehr Funktionalität
hat.
Umgebungen ohne kommerzielle Backup-Systeme müssen in irgendeiner Form auf Skripte zugreifen. Dieser Ansatz ist natürlich für jemanden, der erst mit Oracle, UNIX und dem Skripteschreiben anfängt, nicht ganz trivial und verlangt Einarbeitungszeit. Dafür wird man mit größerer Flexibilität bei Backup und Wiederherstellung belohnt.
Bis Oracle8 benutzte man svrmgr an der Kommandozeile und machte
einen 'Internal Connect', um die Datenbanken zu managen; seit Oracle 9i ist
die ganze Funktionalität unter SQL*Plus zu finden; man muss sich natürlich
'as sysdba' einloggen.
![]()
Die logische Struktur einer Oracle Datenbank - Teil 1
Tablespaces, Instanzen und Datafiles
Instanz -- Eine Instanz besteht aus einer Reihe von Prozessen, über die eine Oracle Datenbank mit dem sog. 'shared memory' kommuniziert. Unter UNIX existiert auf einem System oft mehr als eine Instanz. Auf einer UNIX-Maschine kann man eine Instanz an den Prozessen erkennen, die alle mit dem Muster ora_ORACLE_SID_ beginnen, ORACLE_SID ist der Name der Instanz. Erst wenn eine Oracle Instanz gestartet wurde, kann man auf die Datenbank zugreifen. Unter UNIX startet man eine Instanz an der Kommandozeile mit dem Befehl dbstart und stoppt sie mit dbshut. NT-Datenbanken starten über das Dienste-Fenster: Start --> Einstellungen --> Systemsteuerung --> Verwaltung --> Dienste.
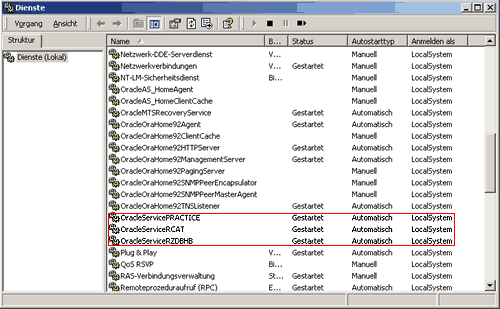
Abb. 1 Hier laufen 3 Instanzen, nämlich PRACTICE, RCAT und RZDBHB.
Zum Unterschied: Datenbank -- Instanz Die eigentliche Datenbank ist genau das, was sich die meisten Leute vorstellen, wenn sie an Oracle denken: Die Datenbank enthält die Daten. Hier finden wir Tabellen, Indizes und weitere wichtige Datenbankobjekte. In der Regel haben Instanzen und Datenbanken eine 1:1-Beziehung, d.h. meistens hat jede Datenbank ihre Instanz, und jede Instanz ihre Datenbank. Viele Oracle-Praktiker benutzen den Ausdruck 'Instanz' und 'Datenbank' daher synonym. Tatsächlich sind diese beiden Entitäten zwar eng verwandt, aber doch unterschiedlich. Eine Oracle Datenbank kann nämlich auch mehrere Instanzen haben; diese Option nennt man Oracle Parallel . Wenn man dann fälschlich von Datenbanken spricht, kann man ins Schleudern geraten.
Bei Oracle stellt der Begriff 'Datenbank'
die physikalische Repräsentation
der gespeicherten Daten dar: Sie besteht aus Dateien auf einer Festplatte. Die
'Instanz' macht , dass man auf die Informationen
in der Datenbank zugreifen kann. Eine oder mehrere Instanzen können auf
einem Einzelrechner oder dem Server laufen; die Datenbank ist auf physikalische
Speichermedien abgelegt, auf die der Server Zugriff hat.
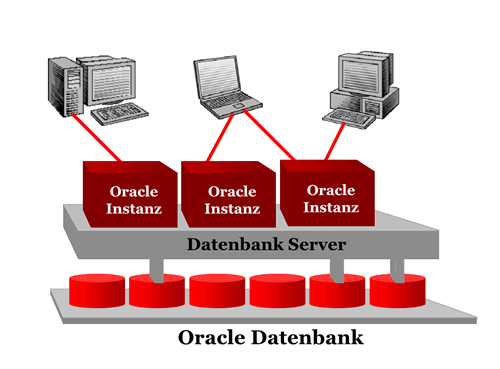
Abb. 2 Schematischer Aufbau einer Oracle Datenbank
Die Instanz ist eine logische Repräsentation: Sie besteht aus Strukturen
im Speicher des Servers und aus laufenden Prozessen. Eine Instanz kann mit einer
(und nur mit einer!!) Datenbank verbunden sein. Instanzen sind kurzlebig, Datenbanken
leben ewig ;-) - sofern sie gut gewartet werden.
User greifen also nie direkt auf die Daten einer Oracle-Datenbank zu, sie schicken
vielmehr Requests an eine Oracle-Instanz.
Als Beispiel aus der 'Real World' könnte man an ein großes Versandhaus
denken. Die Mitarbeiter in der Telefonzentrale und im Lager stellen die 'Instanz'
dar, während die 'Datenbank' das Lager selbst ist. Wenn die Mitarbeiter
Feierabend haben, existiert das Lager weiter, aber es sind keine Bestellungen
möglich. Um mit Oracle zu sprechen: Wenn die Instanz läuft (die Leute
in der Firma arbeiten), können Warenlieferungen und Wareneingänge
im Lager veranlasst werden. Dadurch erst ändert sich der physikalische
Zustand der Datenbank (des Lagers). Wenn die Firma zu ist, können die User
(Kunden, Lieferanten) nicht an die Datenbank (das Lager) herankommen, obwohl
es natürlich physikalisch weiterbesteht.
HIer noch ein paar wichtige Begriffe aus der Datenbankterminologie:
Tablespaces
Alle Daten, die in einer Datenbank gespeichert sind, müssen in einem Tablespace liegen.
Dabei ist ein Tablespace ein logische Struktur: Es gibt also nicht etwa im Filesystem des Betriebssystems ein Verzeichnis namens 'tablespace'. Jeder Tablespace besteht aus mehreren Dateien, den Datafiles. Davon gibt es in einem Tablespace eine oder mehrere, wobei eine einzelne Datafile immer nur zu einem Tablespace gehören kann. Wenn man eine Tabelle erstellt, kann man den tablespace festlegen, in dem sie erstellt werden soll. Oracle wird dann in einer der Datafiles dieses Tablespace einen Plätzchen dafür finden.

Abb. 3 Tablespaces und Datafiles
Hier sieht man also zwei Tablespaces innerhalb einer Oracle Datenbank. Wenn
man in dieser Datenbank eine neu Tabelle erstellt, kann man sie entweder in
den Tablespace DATA1 oder in den Tablespace DATA2 stecken. Physikalische
gesehen, wird sie in einer der Datafiles stehen, die zusammen den Tablespace
darstellen.
Auf der Tablespace-Ebene trifft also die logische Struktur auf die physikalischen Strukturen.
![]()
Die physikalischen Bauteile einer Datenbank
Bevor wir uns weiter mit der Struktur innerhalb einer Datenbank beschäftigen, sollten wir die kleinsten physikalischen Bauteile einer Datenbank kennenlernen.
Noch mal: Bei Oracle stellt der Begriff 'Datenbank'
die physikalische Repräsentation
der gespeicherten Daten dar: Sie besteht aus Dateien auf einer Festplatte.
Wenn man eine Datenbank erstellt, gibt man ihr einen spezifischen Namen. Dieser
Datenbankname kann, wenn er einmal vergeben ist, nicht mehr verändert werden.
Das gilt nicht für die Instanzen, deren Namen geändert werden können.
Jetzt lernen wir die verschiedenen Dateien und Komponenten kennen, aus denen
die Datenbank besteht.
Block -- Ein Block ist das kleinste Datenmenge 'am Stück', die innerhalb der Datenbank bewegt werden kann. Oracle erlaubt es, die Blockgröße in jeder Instanz nach eigenen Wünschen einzustellen. Sie kann zwischen 1024 und 8096 Bytes liegen. In anderen RDBMSs (Relational Database Management Systems) wird ein Block oft als Seite bezeichnet.
Extent -- Ein Extent ist eine Sammlung aufeinander folgender Oracle Blöcke, die so zu nächst größeren Einheiten zusammengefasst sind. Die Größe jedes Extents bestimmt der DBA.
Segment -- Ein Segment besteht aus mehreren Extents, die zu ein und demselben Datenbankobjekt (meist einer Tabelle gehören). Je nach Tabellentyp und erforderlichem Speicherplatz können für eine bestehende Tabelle weitere Segmente allokiert, also 'drangehängt' oder auch weggenommen werden. Ein gutes Beispiel ist ein Rollback-Segment (kommt noch): Ein Rollback-Segment besteht aus allen Extents, in denen Rollback Logs abgelegt wurden. Die Größe eines Rollback Segmentes kan zu- oder abnehmen - je nachdem, wieviele noch nicht 'committete' Transaktionen gerade offen sind. Oracle allokiert Extents zum Rollback Segment, wenn mehr benötigt werden und gibt wieder welche frei, wenn die transaktion abgeschlossen ist.
Datafile -- Eine Oracle Datafile kann entweder eine 'rohe' (eine Festplatte) oder 'gekochte' Datei (aus einem Filesystem) sein. Einmal erzeugt, ist die Syntax für rohe oder gekochte Datafiles gleich. Backup-Skripts müssen aber mit den verschiedenen Dateitypen unterschiedlich umgehen. Soll ein Backup-Skript Datafiles auf 'rohe' Partitionen zugreifen , braucht man dd oder ein ähnliches Betriebssystemkommando, das auch mit einer 'rohen' Partition umgehen kann. cp oder tar würden da nicht funktionieren, denn diese Befehle können nur mit Dateien aus Filesystemen umgehen.
Jede Oracle Datafile enthält einen speziellen Block, den 'Header', der die System Change Number (SCN) der Datenfile enthält. Diese SCN wird jedesmal hochgezählt, wenn sich in der datafile etwas ändert. Die Controlfile (Steuerdatei) schreibt alles mit und kennt immer die aktuelle SCN. Beim Start einer Instanz wird die aktuelle SCN mit den aufgezeichneten SCNs aus jeder Datafile verglichen.
![]()
Physikalische Dateien in einer Datenbank
Ein Tablespace ist eine logische Sicht auf die physikalischen Datenspeicher
einer Oracle-Datenbank.
Es gibt drei wichtige Typen von Dateien in einer Oracle-Datenbank.
Es gibt noch ein paar weitere Dateitypen (z. B. Password Files und Instance
Initiation Files), die eben genannten 3 Typen repräsentieren aber die eigentliche
Datenbank.
Abbildung 4 zeigt die 3 Typen und ihre Zusammenarbeit.
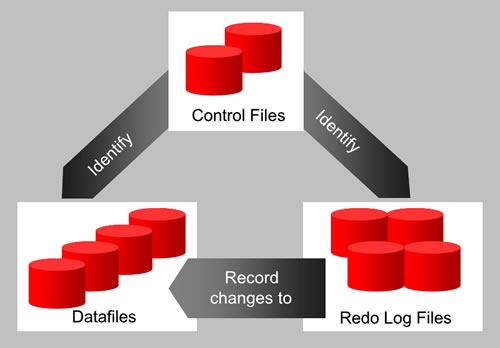
Abb. 3
Mit Oracle9i wurde das Konzept der Oracle Managed
Files (OMFs) eingeführt.
Man braucht nur bestimmte Initialization Parameters
zu spezifizieren , und die Oracle-Datenbank wird automatisch alle Dateien für
die Datenbank erstellen, benennen, managen und ggf. löschen. Das OMF-Konzept
wurde eingeführt, um den großen Aufwand für die Verwaltung zu
reduzieren, der bisher für die Benennung und das Wiederfinden von Dateien
nötig war. So können zumindest in diesem Bereich keine menschlichen
Fehler mehr gemacht werden.
Im nächsten Abschnitt werden wir uns mit der Aufgabe dieser 3 Dateitypen
und ihren Interaktionen beschäftigen.
![]()
Control Files
Die Control File enthält eine Liste von allen anderen Dateien, aus denen die Datenbank besteht, wie z. B. Datafiles und Redo Log Files. Außerdem stehen dort die wichtigsten Informationen über die Inhalte und des Status einer Datenbank, z. B. :
Vor Oracle8 waren Control Files typischerweise kleiner als 1 MB. Seit Oracle 8 enthält sie aber viel mehr Informationen als früher, z. B.über die durchgeführten Backups. Eine Oracle9i - Control File kann daher schnell mehr als 10 MB groß werden. Die Control File der unter Windows erstellten Beispiel-Datenbank ist schon 2,5 MB groß.
Parameter für die Control File
Die Größe einer Control File wird von folgenden Initialisierungsparametern beeinflusst, die Teil der Initialization File sind und mit Erstellung der Datenbank gesetzt werden.
MAXLOGFILES
Maximale Anzahl der Redo Log File Groups
für die Datenbank.
MAXLOGMEMBERS
Maximale Anzahl der MEMBERS für
jede Redo Log File Group.
MAXLOGHISTORY
Maximale Anzahl der Redo Log History Files,
die eine Control File enthalten darf. Diese History
braucht man für eine einfache automatische Recovery.
MAXDATAFILES
Maximale Anzahl der DATAFILES, die
von der Control File gemonitort werden. Wenn man dieses Limit unter Oracle7
überschritten hatte, musste man die ganz Control File wieder neu aufsetzen,
nur um die Anzahl der Datafiles zu erhöhen, die Oracle verwalten sollte.
Bei Oracle 8 und höher bestimmt dieser Parameter den Platz der in der Control
File ausschließlich für Datafiles bereitgestellt wird. Wenn man mehr
Datafiles hinzufügt, als in MAXDATAFILES
spezifiziert sind, wächst die Control File automatisch
mit.
MAXINSTANCES
Die Größe und Anzahl von Instanzen, die die Control File verwalten
kann. Dieser Parameter ist relevant für Oracle
Parallel Server / Real Application Clusters.
Generell ist es für Anfänger empfehlenswert, diese MAX-Werte ziemlich
hoch zu setzen, um nicht später Probleme zu bekommen. Wenn man beispielsweise
zunächst festlegt, dass eine Datenbank 5 Redo Logs zu je zwei Members haben
soll, warum dann nicht gleich MAXLOGFILES auf 20 statt 10 setzen, und MAXLOGMEMBERS
auf 3 statt 2? Der Der Zeitaufwand für das Wiederherstellen einer Control
File ist wesentlich größer, wenn eine Datenbank zu groß wird.
Wichtiger ist es noch, nicht im Interesse von Plattenplatzsparmaßnahmen
den Fehler zu begehen, MAXLOGHISTORY zu stark zu limitieren. Wenn die Control
File einmal nicht genug Platz für die Redo Log History hat, wird eine Recovery
extrem komplex und zeitaufwändig. Meist ist man schon genug unter Zeitdruck,
wenn man eine Recovery machen muss - da würde man sich wegen ein bisschen
billigem Festplattenplatz zusätzlich wertvolle Zeit bei der Beseitigung
eines Disasters einbrocken.
Mehrere Control Files
Eine Datenbank sollte mindestens zwei Control Files haben. Ohne eine einzige aktuelle Kopie der Control File läuft man Gefahr, die Datenbank komplett zu verlieren. Eine Control File zu verlieren, muss nicht fatal enden - es gibt Mittel und Wege, sie wiederherzustellen. Das ist aber immer schwierig und manchmal auch gefährlich; es ist immer eine gute Idee, mehrere Kopien der Control File aufzubewahren. Man kann ganz einfach mehrere Kopien der Control File schreiben lassen, indem man mehrere Speicherorte für die Control Files im Parameter CONTROL_FILES in der Initialization File für eine Instanz angibt, so wie in diesem Beispiel:
CONTROL_FILES = (/u00/oradata/prod/prodctl1.ctl,/u02/oradata/prod/prodctl2.ctl)
|
Dieser Parameter teilt der Instanz mit, wo die Control Files liegen. Oracle kümmert sich darum, dass alle Kopien synchronisiert bleiben, indem sie immer gleichzeitig upgedatet werden.
Viele Oracle-Systeme sind auf redundanten Festplattensystemen installiert, sog. RAID-Systemen. Man könnte nun annehmen, dass man mit einem solchen System gegen alle Unbill geschützt ist. Man sollte aber bedenken, dass man im Falle eine Festplattencrashs schon mit der Hardware genug zu tun hat; danach noch die Control Files weideraufzubauen, kann eine enorme Zeitverzögerung für das Wiederaufsetzen der Datenbank bedeuten. Ein RAID-System schützt auch nicht vor Fehlern durch den 'Faktor Mensch'. Falls jemand aus Versehen das Control File löscht, umbenennt, durch eine ältere Kopie ersetzt oder verschiebt, wird ein RAID-System diesen Fehler treu und brav mitschreiben - und man sitzt im Zweifelsfall ohne oder mit einer falschen Control File da. Im Vergleich zu anderen Aktionen in einer Datenbank ist im Übrigen der Performanceverlust durch das Schreiben multipler Control Files verschwindend gering.
![]()
Datafiles
Datafiles enthalten die eigentlichen Daten, die in der Datenbank verwaltet werden. Das bedeutet: Tabellen und Indices, wo die Daten abgelegt werden, das Data Dictionary, das die Informationen über die Datenstrukturen enthält und die Rollback-Segmente, die das Konsistenzschema implementieren.
Eine Datafile besteht aus Oracle Database Blocks, die wiederum aus den Blöcken des Betriebssystem auf der Festplatte zusammengesetzt sind. Oracle Blocks können zwischen 2 und 32 KB groß sein. Ausnahmsweise kann man Oracle auch mit Very Large Memory (VLM) Support z. B. auf einer DEC Alpha Maschine betreiben, dann kann man sog. Big Oracle Blocks (BOBs) mit bis zu 64 KB benutzen. In den Versionen vor Oracle9i gab es nur eine einzige Blockgröße in einer Datenbank. Seit Oracle9i wird zwar immer noch ein Default Block Size gesetzt, man darf aber bis zu 5 Non-Standard Block Sizes in der Datenbank nutzen. Allerdings gibt es pro tablespace immer nur eine Blockgröße.
Eine Datafile gehört jeweils immer nur zu einer Datenbank und darin wiederum nur zu einem Tablespace. Daten werden in zusammenhängenden Einheiten als Oracle Blocks aus der Datenbank in den Arbeitsspeicher ausgelesen, genauso wie umgekehrt Daten blockweise aus dem Arbeitsspeicher in die Datenbank geschrieben. Datafiles sind die niedrigste Granularitätsstufe zwischen einer Oracle Datenbank und dem Betriebssystem.
Struktur der Datafiles
Der erste Block jeder Datafile ist der Datafile Header. Er enthält kritische Informationen die die Integritätüber die gesamte Datenbank aufrechterhlten. In diesem Header ist am wichtigsten die sog. Checkpoint Structure. Dabei handelt es sich um einen logischen Timestamp, der auf den Punkt zeigt, an welchem zuletzt etwas verändert wurde und ist wichtig für Recovery Situationen. Der Oracle Recovery Prozess bestimmt mithilfe dieses Timestamps im Header einer datafile, welche Redo Logs wieder ausgeführt werden müssen, um die Datenbank wieder auf den aktuellen Stand zu bringen.
Data Blocks, Extents und Segmente
Aus physikalischer Sicht besteht eine Datafile letztlich aus Betriebsystemblöcken.
Aus logischer Sicht haben Datafiles 3 Organisationsstufen: Data Blocks, Extents
und Segmente.
Ein Extent ist ein Satz Datenblöcke,
der innerhalb einer Datafile zusammenhängt. Ein Segment
ist ein Objekt, das aus solchen Extents besteht, wie z. B. eine Tabelle, die
aus einem oder mehreren Extents zusammengesetzt ist. Wenn Oracle Daten updatet,
versucht das DBMS, die Daten in denselben Block zu schreiben. Ist im entsprechenden
Datenblock nicht mehr genug Platz , wird Oracle
die Daten in einen neuen Block schreiben, der auch in einem anderen Extent liegen
kann.
Redo Log Files
Redo Logs protokollieren mit, welche Veränderungen an einer
Datenbank nach Transaktionen oder internen Oracle Aktivitäten vorgenommen
werden. Oracle hält zunächst alle veränderten Blocks im Cache.
Falls eine Instanz abstürzt, kann es vorkommen, dass veränderte Blocks
noch nicht in die Datenfiles geschrieben worden sind. Mit Hilfe der Redo Logs
ist Oracle im Stande herausfinden, welche Veränderungen von dem Verlust
des Caches betroffen sind, un diese Veränderungen wieder einzuspielen.
Redo Logging kann mit dem Attribut NOLOGGING in einem SQL statement unterdrückt
werden, um beispielsweise große Operationen zu beschleunigen, die aber
einfach manuell wiederauszuführen wären (Index erstellen lassen o.ä.).
Außerdem kann man auch Tabellen oder ganze Tablespaces mit dem NOLOGGING
-Attribut flaggen.
Man kann das Logging durchaus auch generell abschalten, wenn man so schnell
wie möglich Backups von den Veränderungen in der Datenbank macht,
um die neu erzeugten oder veränderten Objekte im Fehlerfall nicht zu verlieren.
Redo Logs mehrfach ablegen
Oracle benutzt für das Management der Redo Log Files eine eigene Terminologie. Jede Oracle-Instanz hat ihren eigene Redo Thread, um die Veränderungen an der Datenbank aufzuzeichnen. Ein solcher Thread besteht aus Redo Log Groups, von denen wiederum jede aus einem oder mehreren Redo Log Members bestehen. Man kann sich vereinfacht jede Redo Log Group als einzelnes 'Redo Logbuch' vorstellen, von dem Oracle mehrere Kopien vorhält, um die Integrität dieser wichtigen Redo-Informationen aufrechtzuhalten. Wir sprechen vereinfacht - wenn auch nicht ganz korrekt - von einer Redo Log Gruppe als einem 'Redo Log File'.

Abb. 4 zeigt einen Redo Thread mit seinen Groups und Members. Jede Gruppe hat
2 Members, d.h. jedes Redo Log wird gespiegelt.
Sind mehrere Members in einer Gruppe, wird jedes Redo Log mehrfach
gespiegelt. Für das Vorhalten von Mehrfachkopien sprechen prinzipiell dieselben
Argumente wie bei den Control Files, denn die Redo Logs enthalten ebenfalls
wichtige, ansonsten möglicherweise nicht wiederherstellbare Informationen.
Einfache Redundanz der Festplatte schützt nicht vor Fällen, in denen
Redo Logs aufgrund menschlichen Versagens korrumpiert oder gelöscht werden.
Es gibt zwar zwei Möglichkeiten, bei Verlust den statischen Teil eines
Redo Logs wiederherzustellen, aber eine echte Reproduktion eine verlorenen Redo
Logs ist nicht möglich.
Oracle schreibt alle Redo Log Members synchron und betrachtet das Schreiben
eines Redo Logs erst dann als abgeschlossen, wenn auch die letzte Kopie upgedatet
ist. Die Performance hängt also am langsamsten Mitglied!
Was macht Oracle mit den Redo Logs ?
Sobald eine Redo Log File vollgeschrieben ist, wechselt Oracle automatisch zum nächsten und beginnt, dieses vollzuschreiben. Man spricht von einem Log Switch. Kurz vor diesem Zeitpunkt wird ein Checkpoint markiert. Man spricht beim Wechsel zu einem neuen Redo Log von einem Log Switch. Ist es einmal durch alle (in unserem Beispiel : 3) Gruppen durch, geht es wieder zum ersten zurück und überschreibt dieses. Dabei verfolgt Oracle diesen Schreibvorgänge, indem es die Redo Logs mit der Redo Log Sequence Number durchnummeriert und diese Nummer natürlich in jedes Redo Log File schreibt.
Beispiel: Wir nehmen an, die 3 Redo Log Files heißen redolog1.log,
redolog1.log und redolog3.log. Die ersten Redo Log
Sequence Numbers sind dann 1, 2 und 3. Wenn Oracle zur ersten Datei, dem redolog1.log
zurückkehrt, weil redolog3.log vollgeschrieben ist, wird redolog1.log
überschrieben und bekommt die Redo Log Sequence Number 4 zugewiesen. Sobald
redolog1.log voll ist, wird redolog1.log überschrieben
und erhält die Redo Log Sequence Number 5 usw.
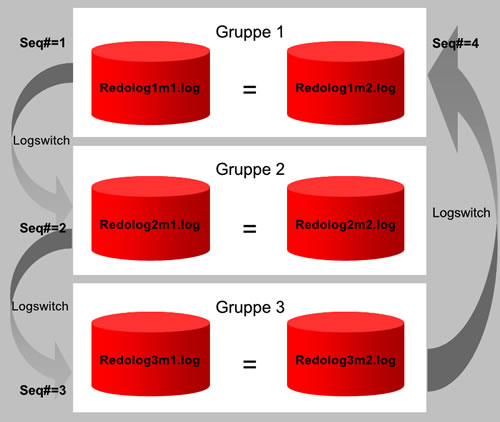
Abb. 5 zeigt das Recycling der Redo Logs.
Checkpoint
Ein Checkpoint ist ein Zeitpunkt, zu welchem alle Daten aus dem
Arbeitsspeicher auf die festplatte geschrieben sind. Ein Oracle DBA kann mit
dem Befehl 'alter system checkpoint' einen Checkpoint erzwingen, aber ein Checkpoint
wird auch automatisch gesetzt bevor die Datenbank einen Logswitch macht.
![]()
Archivierte Redo Logs und der ARCHIVELOG-Modus
Wie behält man aber die kritischen Informationen aus den
Redo Logs, wenn Oracle sie immer wiederverwendet und überschreibt?
Angenommen, seit dem letzten Backup sind die die Redo Logs 1 bis 15 geschrieben
worden. Wenn man 3 Redo Logs Files hat , dann wären immer nur die letzten
drei (also 13, 14 und 15) verfügbar, so dass man die Datenbank doch nur
zum letzten kompletten Backup wiederherstellen könnte.
Die Lösung: Die Redo Logs werden archiviert, sobald sie gefüllt sind.
Man spricht daher von den Online Redo Logs
und meint damit die o. g. Betriebssystemdateien, durch die Oracle gerade seine
Runden dreht (also die mit den Nummern 13, 14, und 15).
Mit Archived Redo Logs meint man die
Kopien der 'alten' Redo Logs, die vor dem Überschreiben gesichert worden
sind (also die mit den Nummern 1 bis 12).
Eine Oracle Datenbank kann in zwei Modi laufen:
NOARCHIVELOG - wie der Name schon sagt: Die Redo Logs werden nicht archiviert. Damit reduzieren sich natürlich die Möglichkeiten einer effizienten Wiederherstellung im Grund auf das letzte komplette Backup.
ARCHIVELOG: Sobald Oracle einen Logswitch zu einem neuen Redo Log macht, wird das vorhergehende Redo Log archiviert. Ein Redo Log kann auch erst dann recycelt werden, wenn es erfolgreich archiviert worden ist. Die archivierten Redo Logs stellen zusammen mit den gerade aktuellen Online Redo Logs eine vollständige Historie aller Veränderungen an der Datenbank dar. Damit kann Oracle alle per 'Commit' abgeschlossenen Transaktionen bis exakt zum Zeitpunkt des Fehlers nachvollziehen.
ARCHIVELOG Modus und automatisches Archivieren
Um in einer Oracle Datenbank das automatische Archivieren einzurichten, müssen zwei Schritte getan werden - zur richtigen Reihenfolge bitte Punkt 4 beachten!
SQL> ALTER DATABASE ARCHIVELOG |
LOG__ARCHIVE_START = TRUE |
|
|
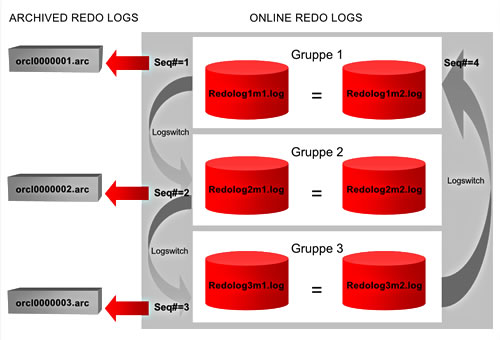
Abb. 6 Recycling der Redo Logs mit Archivierung
Man muss sich auch unbedingt darum kümmern, dass im Archive Log Zielverzeichnis genug Platz für die Archive Logs ist: Oracle stoppt, wenn es keinen Plattenplatz für Archive Logs hat. Die archivierten Redo Logs sind kritisch für eine vollständige Datenbak-Recovery. Seit Oracle 8 kann man auch die mehrere Kopien der Archive Logs in unterschiedliche Zielverzeichnisse schreiben lassen. Für Details verweise ich hier auf die Dokumentation aller Initalisierungs-Parameter, die mit LOG_ARCHIVE* beginnen.
Je nachdem, wieviel Verkehr auf einer Datenbank herrscht, können sich
im Archive Log Verzeichnis eine ganze Menge Dateien ansammeln. Oracle kümmert
sich nicht um den Plattenplatz. Daher muss man sich einen Cron-Job aufsetzten,
um dieses Verzeichnis immer rechtzeitig zu leeren. Wenn die Dateien zuverlässig
auf irgendeinem Backup-Medium abgelegt werden, kann man sie natürlich zügig
wieder löschen und den Platz wieder freigeben. Je mehr Logs auf der Festplatte
liegen, umso schneller ist andererseits eine eventuelle Wiederherstellungsoperation.
Gelegentlich muss man ja von einem älteren Backup wiederherstellen (Das
aktuellste Backup könnte ja beispielsweise korrupt sein).
Wenn alle Archive Logs seit dem Abschluss des vorletzten Backups noch
auf der Platte sind, ist die Recovery ein Klacks. Wenn sie nicht mehr auf der
Platte liegen, müssen sie beispielsweise von Band wiederaufgespielt werden.
Das kann Probleme mit dem verfügbaren Speicherplatz geben. Deshalb wird
auch immer empfohlen genug Platz bereitzustellen, um alle Archive Logs von zwei
üblichen vollständigen Backup-Perioden ablegen zu können.
Beispiel: Sie machen immer nachts ein vollständiges Datenbankbackup. Dann
sollten Sie Platz für mindestens alle Redo Logs sein, die an zwei hochfrequentierten
Tagen anfallen. Macht man nur alle zwei Wochen ein Backup, braucht man genug
Speicherplatz für die Redo Logs von zwei Wochen. Das ist natürlich
auch ein Argument, jede Nacht ein Backup zu machen....
![]()
Andere wichtige Dateien
Initialization Parameter File
tbd
Alert Log File und Trace Files
tbd
Password File
tbd
![]()
Die logische Struktur einer Oracle Datenbank - Teil 2
Komponenten einer Instanz und Hintergrundprozesse
Ein Oracle-Instanz besteht aus einem Bereich im Arbeitsspeicher (sog. Area of Shared Memory) und einer Reihe von Hintergrundprozessen. Die Area of Shared Memory für eine Instanz heißt System Global Area (SGA).
![]()
Wichtige Operationen und Begriffe
Transaktion
Unter Transaktion versteht man eine Aktivität von User oder
DBA, die eine oder mehrere Attribute in einer Oracle-Datenbank ändern.
Setzt man eine Gruppe von Befehlen zwischen begin transaction und
end transaction wir die ganz Gruppe als eine Transaktion
behandelt. Logisch gesehen modifiziert auch eine solche Transaktion eine oder
mehrere Attribute in einer oder mehreren Tabellen einer Datenbank, physikalisch
werden dabei einer oder mehrerer Blocks überschrieben.
Was passiert während einer Transaktion?
Rollback Segment
Zur Wiederholung: Ein Segment umfasst immer alle Extents, die zu einem Datenbankobjekt
(beispielsweise einer Tabelle) gehören. Ein Rollback Segment umfasst also
alle Extents eines Rollback Logs. . Bevor ein neuer Eintrag in die Datenbank
physikalisch auf die Festplatte geschrieben wird, wird sozusagen ein 'Vorher-Schnappschuss'
für den Fall aufgenommen, dass die Transaktion rückgängig gemacht
werden muss, im Falle eines sogenannten 'Rollbacks'. Dieser Vorher-Schnappschuss'
wir in einem Rollback Log abgelegt, das wiederum im Rollback Segment liegt (
es kann innerhalb einer Instanz auch mehrere Rollback Segmente geben, und man
kann einer Transaktion vorschreiben, ein bestimmtes Rollback-Segmente zu benutzen.).
Oracle schreibt allerdings zu einer Zeit immer nur in einen Extent eines Rollback
Segments. Auch diese Extents werden in einem zyklischen Vorgehen beschrieben:
Nach und nach werden die Extents gefüllt, bis alle voll sind; dann geht
Oracle zurück zum 'ersten' Extent und fängt an, diesen zu überschreiben.
Oracle weigert sich allerdings, Extents zu überschreiben, in denen es uncomittede
Transaktionen aus der gleichen Transaktion (also einen Teil des selben 'Vorher-Schnappschuss')
findet, denn das Zustandsbild von vor der Transaktion muss ja komplett erhalten
werden, bis die Transaktion committed ist. Oracle weist dem Rollback dieser
langen Transaktion dann zusätzliche Extents zu, damit es genug Platz für
den ganzen 'Vorher-Schnappschuss' hat. Erst wenn alle Transaktionen committed
sind, die zu einem Rollback gehören, werden die benutzten Extents wieder
für das überschreiben durch das nächste Rollback Segment freigegeben.
Braucht ein Rollback weniger Extents, setzt Oracle nicht benötigte Extents
frei und schrumpft so das Rollback Segment auf die Mindestgröße.
Ein Rollback Segment wir übrigens immer erzeugt: das System Rollback Segment. Es wird im System Tablespace abgelegt. Aber weder dieses Rollback Segment, noch sein Tablespace reichen für eine normale Produktionsdatenbank aus. Darum wird ein DBA zusätzliche Rollback Segmente in anderen Tablespaces erzeugen und das System Rollback Segment offline setzen. Es ist üblich, einen Tablespace ausschließlich für Rollback Segmente zu erzeugen. Oracle weist Transaktionen nun reihum Rollback Segmente zu ( oder auch nur ein spezielles, wenn es so konfiguriert wurde). Indem man das System Rollback Segment offline setzt, kann man sicher sein, dass ihm keine Transaktionen zugewiesen werden. So kann sich der Tablespace anderen Aufgaben widmen, ohne ,mit den Rollback-Aufzeichnungen behindert zu werden.
Warum reite ich so auf den Rollback Segmenten herum? Weil sie für die Datenbank-Recovery eine einzigartige Rolle spielen. Wenn man sich vor Augen führt, dass Rollback Segmente abgespeichert werden noch bevor die Änderungen an den geänderten Blocks auf Festplatte geschrieben werden, verseht man, dass diese Informationen bei einem Crash für die anschließenden Recovery unverzichtbar sind, um die Datenbank wieder in einen konsistenten Status zu versetzen. Man braucht sie, um ein Rollback von nicht abgeschlossenen Transaktionen durchführen zu können, indem die betroffen Blöcke in ihren 'Vor-der-Transaktion-Status' zurück zu schreiben. Denn das ist ja der Sinn von Rollback-Segmenten.
Aus dieser Einschränkung ist folgt: Während ein Rollback Segment online wiederhergestellt werden kann, kann ein normaler Tablespace nicht wieder online gesetzt werden, bis das Rollback Segment, das ihn benutzt, komplett zurückgeschrieben ist. Daher erlaubt Oracle nicht, dass Instanzen wieder hochgefahren und geöffnet werden, bis all ihre Rollback Segmente wieder verfügbar sind. Versucht man die Datenbank ohne sie zu öffnen, gibt Oracle den Fehler 'rollback segment segment_name specified not available_' aus.
Startup
tbd
Shutdown
tbd
![]()
Petra Haberer Version
0.0.6